Попытаюсь объяснить еще раз.
Программа "Свежий взгляд" (онлайн) ловит много лишнего. Для того, чтобы максимально приблизиться к желаемому, я выставляю в ней настройки (сверху вниз) 30 - 1000 - 0. Это резко сокращает мусорные результаты, но и тогда мусор остается.
Мне надо, чтобы ловились (подсвечивались) одномоментно (по аналогии со "Свежим взглядом")
все повторы всех возможных сочетаний букв (не менее заданной мной длины в символах, без пробелов, независимо от регистра и языка) по всему тексту, которые найдены в тексте на расстоянии друг от друга не более заданного мной расстояния в символах, причем деление текста на абзацы, переводы строк, пустые строки — всё это не должно играть никакой роли .
Минимальную длину буквосочетания я должен задать для того, чтобы не высвечивались повторяющиеся союзы и предлоги — "и", "в", "на" и т. п.
Максимальное расстояние между повторами ограничивается, потому что "работ" и "работ" в начале и в конце текста — это никакая не "тавтология", это никого не волнует, а цель программы — обнаружить стилистические погрешности текста — та же цель, что и у программы "Свежий взгляд".
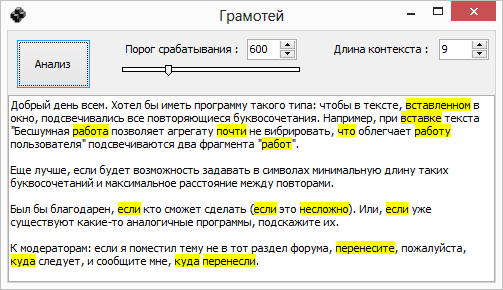
Поясняю на примере. Например, я задал в настройках программы минимальное число символов — 5 и максимальное расстояние между повторами — 300 знаков.
В таком случае по всему тексту подсветится сочетание "работ" если между "работ" и "работ" расстояние не больше 300 знаков. Если между этими повторами 310, 350, 400 знаков, то они не подсвечиваются.
В тот же время в том же тексте по всему тексту будет подсвечено "польз" (если между "польз" и польз" будет не больше 300 знаков), будут подсвечены также "отлич", "запас", "революц", "капитал" и т. д. — все возможные найденные в тексте сочетания букв не меньше указанного размера (5 знаков). И не будет подсвечено "преп", "курс" и т. п., так как эти сочетания имеют длину меньше 5 знаков.
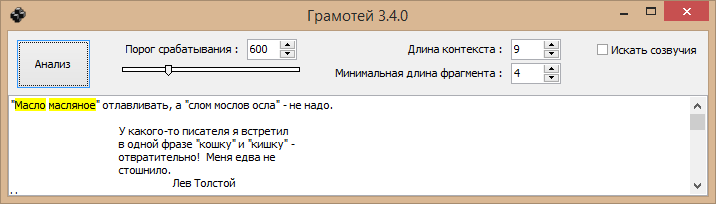
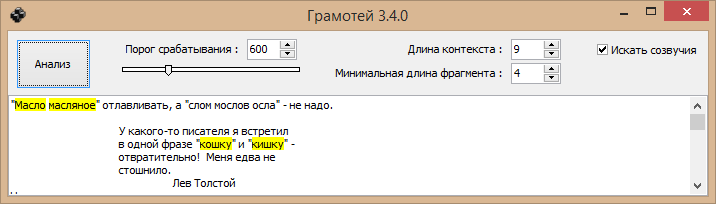
Вставляешь в окно программы текст, нажимаешь кнопку, видишь все подсветки. Вот всё, что требуется
Если это реализовать, это будет круче, чем "Свежий взгляд", у которого, как я понимаю, нет альтернатив (гуглил-гуглил и ничего не нашел), но который (и в онлайн-версии) грешит недостатками, о которых я уже писал: и невнятные настройки, и невнятный хелп (на мой взгляд), и поиск повторов производится только в пределах абзаца, и невозможно сохранить свои настройки в онлайн-версии. Плюс к тому офлайн-программа работает из командной строки в офлайне (и это в эпоху Windows!)
Так что,
KDPoid, родина (в моем лице

) на Вас очень надеется!
P. S. Упс... Что-то я вдруг задумался: если задан размер 5 знаков, то, получается, по-моему, что должны быть подсвечены одновременно и "истор", и "истори" в словах "исторический" и "история"?
Если разными цветами подсвечивать, то получится хрен знает что. Если одним — то в принципе нормально — будет отмечен максимальный по длине совпадающий кусок слов.
Но можно и такой подход применить, как вариант: подсвечивать в тексте не куски слов, а целиком слова, в которых встречается хоть какой-либо повтор, соответствующий моим настройкам. Тогда, правда, совпадающая часть слов не будет выделена, но ее ведь и так можно отловить глазами. Например, в предложении "До исторического материализма мало кто верил в такие истории" программа находит повтор "истори" и подсвечивает два слова — "исторического" и "истории".
Вот такие варианты, если, конечно, это под силу программисту.