Ну вот так получается это работает:
Действует как плагин Quite Imposing от Акробата (тока ничего не надо распознавать в Акробате и в PDF-XChange Tools - No OCR!).
И всего за 5 шагов.
1/ Запускаем PDF Tools и выбираем меню наложения пдф файлов:
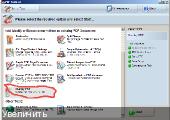
2/ Выбираем сначала файл OCR, выведенный в FR8 как text o v e r image PDF тип файла:
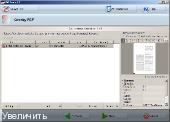
3/ Выбираем файл наложения, полученный в PDF Tools предварительно из multipage TIFF файла в Букресторере:
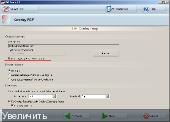
4/ Задаем папку для файла на выходе и его название:
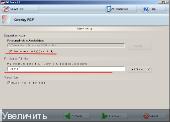
5/ Готовимся получать выходной файл 2,36 Мб на 14 книжных страницах =
168,5 Кб / стр , давим на кнопку Finish:
Наслаждаемся обалденным качеством изображения, недоступным FineReader'у, причем с возможностью поиска по OCR, недоступного Акробату!

Пока складывается такая схема оцифровки книг с учетом последних экспериментов (сначала PDF, потом DJVU, не наоборот, так во всем мире!):

Для PDF и OCR офисных доков 100% хватит заглаза самой проги PDF Tools!
Выше речь шла тока о проблемах сканировании книг и сложной полиграфии - разные шрифты: сериф, сан сериф, нормал, болд, курсив в тексте для распознавания (OCR). Распознать это все в одном тексте даже Акробатом и не пытайтесь. - Нужен FineReader.
 Что уж там про ,другие проги.
Что уж там про ,другие проги. 






 Мне казалось, что он просто добавляет к исходному графическому файлу свой текстовый слой, полученный в результате операции распознавания.
Мне казалось, что он просто добавляет к исходному графическому файлу свой текстовый слой, полученный в результате операции распознавания. 


