1. Считаю, что в форуме "в программах" (и не только) нужно ввести к каждой программе некую таблицу безусловных ошибок или недостатков программ или как-то это оформить в шапке - по ссылке на отдельной странице или типа того. Там же можно было бы постить новые ошибки и удалять исчерпанные. Т.е. только пункты с кратким, но достаточным описанием и безо всякого флуда. Для чего все это - объяснять не нужно, надеюсь, - юзеры постят, а для адекватных авторов - это халявные результаты тестирования.
Ибо нужно понимать, что всегда есть некая "критическая масса", когда недостатки перевешивают и происходит переход на конкурентный софт...
2. Пример ошибки (по ABBYY FineReader). Меня она задолбала и вижу пока решение в виде самодельной фичи, ожидающей окно ошибки и обрабатывающей ее при возникновении, т.к. авторы модуля "HotFolder" (версии Корпорейт) об этом не позаботились и вообще смысл этого модуля данная ошибка сводит на нет... (Сейчас сижу и жду ее появления, т.к. прежде не делал ее скринов и описаний). Вижу эту ошибку, к слову, уже несколько лет и во всех версиях и сборках где есть "HotFolder".
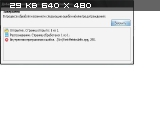
Скрин первого окна ошибки

выключается нажатием "отмена".
Скрин второго окна ошибки

выключается нажатием "да".
Дальше программа нормально продолжает работу.
Но ошибка не обрабатывается самой программой автоматически. Т.е. если вы утром хотели проснуться и увидеть выполненную работу, то это как повезет... Может выскочить ошибка как только вы отошли от компьютера...
Для "forum.ru-board": если п.1 не поддержится, то больше время тратить на это не буду.
3. Неадекватное использование ресурсов компьютера - грузит только на 100% память и процессор.
Мой ПК глухо "висит" на Core i7 920 с 3Гб 3-х канальной памяти.