В принципе проблему можно решить, если сканировать в цветной PDF из самой ABBYY FineReader 9.0 Sprint, но также хотелось бы задать такую настройку и для EPSON Scan - Скан. в PDF, так как ABBYY FineReader 9.0 Sprint по своему усмотрению может сделать PDF полностью двуцветным. Но с 1й стороны это и хорошо, что сильно уменьшается размер файла, а с другой стороны - хотелось бы сохранить максимальную похожесть документа.
» ABBYY FineReader
Кто-нибудь может подтвердить/опровергнуть?
На Win 8.1, FR 12.0.101.264 и двух мониторах: Screenshot Reader при выделении области на главном мониторе рисует рамку на дополнительном мониторе, а не на главном, как должен.
Добавлено:
Точнее так: пока рисую рамку, при зажатой ЛКМ рамка отображается с сильным смещением влево (так, что попадает на соседний монитор), как только отпускаю ЛКМ рамка появляется в том месте, где и рисовалась.
На Win 8.1, FR 12.0.101.264 и двух мониторах: Screenshot Reader при выделении области на главном мониторе рисует рамку на дополнительном мониторе, а не на главном, как должен.
Добавлено:
Точнее так: пока рисую рамку, при зажатой ЛКМ рамка отображается с сильным смещением влево (так, что попадает на соседний монитор), как только отпускаю ЛКМ рамка появляется в том месте, где и рисовалась.
Цитата:
hogu77: Кто-то сравнивал межу собой .382 и .264, там что-то важное или как всегда?
Попробовал давеча триал .382 — по-прежнему из проверки исключены русские слова с ударениями.
Для меня это один из значительных багов, ради которого стоило бы обновиться.
Местные завсегдатаи писали, что на форуме разрабов были жалобы на что-то ещё.
Пофиксили ли что-то из того — не в курсе.
Цитата:
Shangry: это сейчас похоже мода такая пошла - ругать, критиковать, разоблачать, изобличать и т.д.
Не вы ли несколько раз разоблачали и ругали ABBYY по поводу их урезанного в процессорном плане корпората?

Одно дело "мода", другое — когда для ругани есть повод. А его абивцы регулярно предоставляют,
выпуская полусырые версии по ~150 баксов и оттачивая их на нас.
ALEX666999
Цитата:
Когда есть причина/повод, так именно о них и говорят, именно их и обсуждают. Конкретные баги, конкретные недоделки и недодуманности
Чаще же видишь фразы уровня "опять ничего нового", "мне хочется, чтобы он работал вот так и вот так, а он работает совсем не так - значит программа никуда не годится", "в версии *** нет ничего принципиально нового". Или же просто бурный поток эмоций фактически ни чем, лишь бы лишний раз побрюзжать.
Ну и сразу вспоминается известное: "Мне не нравится этот остров, мне не нравится это море... мне здесь вообще все не нравится!!!".
Цитата:
А версий любой сложной программы, полностью вычищенных ото всех ошибок, в природе вообще не бывает.
Что же до сырости FR, то погонял на своих задачах 12-ю версию - работает вполне нормально, Error-окошками сыплет нисколько не чаще последнего релиза 11-й версии. Да и интерфейс наконец-то начали до ума доводить, что давно уже пора было.
Цитата:
Одно дело "мода", другое — когда для ругани есть повод.
Когда есть причина/повод, так именно о них и говорят, именно их и обсуждают. Конкретные баги, конкретные недоделки и недодуманности
Чаще же видишь фразы уровня "опять ничего нового", "мне хочется, чтобы он работал вот так и вот так, а он работает совсем не так - значит программа никуда не годится", "в версии *** нет ничего принципиально нового". Или же просто бурный поток эмоций фактически ни чем, лишь бы лишний раз побрюзжать.
Ну и сразу вспоминается известное: "Мне не нравится этот остров, мне не нравится это море... мне здесь вообще все не нравится!!!".
Цитата:
выпуская полусырые версии
А версий любой сложной программы, полностью вычищенных ото всех ошибок, в природе вообще не бывает.
Что же до сырости FR, то погонял на своих задачах 12-ю версию - работает вполне нормально, Error-окошками сыплет нисколько не чаще последнего релиза 11-й версии. Да и интерфейс наконец-то начали до ума доводить, что давно уже пора было.
Протестировал FR12СЕ на неск.документах - не понравилась по сравн.с FR11СЕ. Во первых не определяет оптимальную резолюцию правильно и приходится неск.раз ее подкорректировать, что нельзя сказат о 11. Прямые разметки линии в документах что в 11, 12-ая их искривляет. Как по мне-хуже, откатился на 11.
На просторах нашел
пример работы с дореволюционной орфографией
ABBYY FineReader 11 и ABBYY FineReader 12
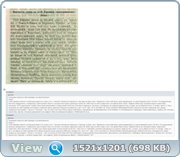
что-то новое он понял, а что-то забыл
пример работы с дореволюционной орфографией
ABBYY FineReader 11 и ABBYY FineReader 12

что-то новое он понял, а что-то забыл
ABBYY FineReader 12. При сканировании делит страницу пополам что делать? Помогите.
Monster2011
Настройки -> Сканировать/Открыть
Снимите галочку на пункте "Делить разворот книги".
Настройки -> Сканировать/Открыть
Снимите галочку на пункте "Делить разворот книги".
Подскажите пожалуйста:
FR11 паралельно со сканированием начинал распознавать текст. Как в FR12 добиться аналогичного режима? Поскольку при сканировании распознавание не запускается, а при распознавании запустить скан не позволяет. Спасибо.
FR11 паралельно со сканированием начинал распознавать текст. Как в FR12 добиться аналогичного режима? Поскольку при сканировании распознавание не запускается, а при распознавании запустить скан не позволяет. Спасибо.
Подскажите пожалуйста:
Windows 8.1 Update 1 x64
FinerReader 12 12.0.101.388 Corporate Edition
При запуске пишет что не удалось прочитать c:\windows?
Нужны админские права чтобы запустить!?
Заранее благодарен!
Windows 8.1 Update 1 x64
FinerReader 12 12.0.101.388 Corporate Edition
При запуске пишет что не удалось прочитать c:\windows?
Нужны админские права чтобы запустить!?
Заранее благодарен!
Если программа сообщает об ошибке поиска msxml6.dll, то просто положите её рядом с бинарником FR. Подробнее смотрите MSDN.
Victor_VG
Просто положить msxml6.dll рядом с портабл-версиями (как и в систем32) проблему не решило - только установкой.
да и сообщает fr об этом непредметно - какой-то "Сlass not registered" (а причастность к этому msxml6 нагуглилась в факе офсайта).
Просто положить msxml6.dll рядом с портабл-версиями (как и в систем32) проблему не решило - только установкой.
да и сообщает fr об этом непредметно - какой-то "Сlass not registered" (а причастность к этому msxml6 нагуглилась в факе офсайта).
maxvlas
Цитата:
Все-таки, как кажется, больше забыл старое, чем понял новое, к сожалению...
Цитата:
что-то новое он понял, а что-то забыл
Все-таки, как кажется, больше забыл старое, чем понял новое, к сожалению...
Задача, сделать из PDF без текста, PDF с текстом под картинкой. Пробую разные настройки в FR12, PDF на выходе всегда хуже качеством с размытым текстом.
soliduz
Цитата:
Извлечь OCR-текст из документа PDF сделанного FineReader с помощью Callas PDF Toolbox v5.0 (портабельную версию легко найти в сети), или с помощью Acrobat.
Вставить OCR-текст в оригинальный PDF c помощью PDF-XChange Tools 4.0 или Callas PDF Toolbox v5.0
Цитата:
...PDF на выходе всегда хуже качеством с размытым текстом
Извлечь OCR-текст из документа PDF сделанного FineReader с помощью Callas PDF Toolbox v5.0 (портабельную версию легко найти в сети), или с помощью Acrobat.
Вставить OCR-текст в оригинальный PDF c помощью PDF-XChange Tools 4.0 или Callas PDF Toolbox v5.0
Доброго времени суток! Не знаю, было ли тут в форумах, но в гугле не нашла решение проблемы: на ХР SP2 не стает ни одна версия FR (пробовала 10, 11, 12). Пишет: "Ошибка при запуске службы Abbyy FineReader 11 PE Licensing Service (ABBYY.Licensing.FineReader.Professional.11.0). Убедитесь, что у вас имеются разрешения на запуск системных служб". Запуск от имени админа не помогает.
Жадаев А. Г.
Сканирование и распознавание текстов.
Самоучитель по работе с ABBYY FineReader 10.

М.: ДМК Пресс | 2010 | ISBN: 978-5-94074-595-2 | 250 стр. | PDF | 19.3 MB
Сделал наследуемое увеличение (масштаб) в закладках.
Добавил линки в Содержание для удобной навигации по книге (sendfile.su)
https://yadi.sk/
Сканирование и распознавание текстов.
Самоучитель по работе с ABBYY FineReader 10.
М.: ДМК Пресс | 2010 | ISBN: 978-5-94074-595-2 | 250 стр. | PDF | 19.3 MB
Сделал наследуемое увеличение (масштаб) в закладках.
Добавил линки в Содержание для удобной навигации по книге (sendfile.su)
https://yadi.sk/
ComboFZ
Очень кстати! Как говорится, просто на блюдечке...
Цитата:
Действительно, очень удобно!
Очень кстати! Как говорится, просто на блюдечке...
Цитата:
Добавил линки в Содержание для удобной навигации по книге
Действительно, очень удобно!
ComboFZ
Цитата:
В каком просмотрщике и как это увидеть?
STDU не видит
Цитата:
Сделал наследуемое увеличение(масштаб) в закладках.
Добавил линки в Содержание для удобной навигации по книге (sendfile.su)
В каком просмотрщике и как это увидеть?
STDU не видит
edelvice
Вам же ответили на другом форуме. Попробуйте отлючить встроенный фаервол.
Вам же ответили на другом форуме. Попробуйте отлючить встроенный фаервол.
Как же хочется ругаться матом на разрабов. Нужно было обработать около 14000 PDF. Понятно, что использовать для этого можно только Hot Folder. Загружаю в Hot Folder в 12-й версии, начинаются немыслимые тормоза -- примерно один файл в 10 мин. Пробую 11-ю версию -- примерно то же самое. Сколько я всего перепробовал. Наконец, пошел искать по форумам. И что бы вы думали -- начиная с 10-й версии идет ограничение по числу ядер -- в 11-й версии на одно ядро, в 12-й -- на два. Еще ограничили 5000 стр. в месяц. Какой облом для тех, кто покупает корпоративки 
ЗАЧЕМ??? Единственная гипотеза -- чтобы вынудить предприятия переходить на Recognition Server
Короче, пришлось ставить 10-ю -- 10 файлов в минуту, все прекрасно... Вот только странно -- в 11-12-й все же должно было бы быть побыстрее: 1 файл в 10 минут -- это как-то совсем жестко.
ЗАЧЕМ??? Единственная гипотеза -- чтобы вынудить предприятия переходить на Recognition Server
Короче, пришлось ставить 10-ю -- 10 файлов в минуту, все прекрасно... Вот только странно -- в 11-12-й все же должно было бы быть побыстрее: 1 файл в 10 минут -- это как-то совсем жестко.
ghosty
Именно по причине этого идиотизма (скорее всего и впрямь коммерческой природы) и приходится до сих пор жить на FR 10 CE.
Хвала Аллаху, у нас им успели обзавестись еще до появления 11-й версии, так что поточное распознавание пока что, тьфу-тьфу, не проблема. А с учетом того, что с сайта ABBYY можно скачать относительно свежий релиз 10-й версии, в которой вычищено немало ошибок, так и совсем приличная жизнь.
Кстати, этот релиз помечен 2013-м годом (даты файлов - конец сентября). Похоже не у нас одних он такой вот долгожитель, все еще присылают баг-репорты и все еще чистят от багов.
Что же до 12-й версии, то есть интересная идея по приведению ее в нормально дееспособный вид. Покупаем FR 12 CE, ставим, регистрируем, активируем и т.д. Затем применяем лекарство от жадности.
Результаты:
- за программу честно уплачено, значит у производителя претензий быть не должно;
- при любой проверке она будет выглядеть, как нормальная лицензионная программа;
- работать можно совершенно нормально, безо всяких надуманных ограничений.
Цитата:
Это было вполне очевидно с самого начала. Видимо у двух отделов ABBYY - который занимается Recognition Server и который занимается обычным FR - в какой-то момент произошла нестыковка планов. И вторые не сообразили, что их новая выдумка, HotFolder - потенциальный конкурент первых.
Основное здесь недоумение - а зачем тогда вообще оставили HotFolder?
Убрали бы вообще к чертям собачьим и закрыли бы тем самым проблему. Но нет, оставили, однако всего лишь на уровне демонстрации возможностей пакетной обработки и не более того.
Цитата:
Ну так сами же сказали - ограничитель по процессорному ресурсу. Убрать его - и пакетная обработка начинает работать заметно быстрее, чем в "десятке".
Правда может появиться другая проблема.
В 10-й версии HotFolder обрабатывал PDF поштучно - открыл, распознал, закрыл, открыл следующий и т.д. В 11-й и 12-й сделано по другому - сначала открывает в свой пакет _все_ PDF, лежащие в папке для обработки и только потом начинает их обрабатывать.
С этого обычно возникают две головных боли. Во-первых, место под TMP-файлы - его нужно иметь в размере всей кучки исходных PDF (причем не в объеме самих PDF, а в объеме их содержимого, пересчитанного в TIFF - открываются сканы в несжатом растре). Во-вторых, если по ходу работы HotFolder программа вдруг отрубилась (или Windows на перезагрузку вылетело), то после запуска FR обработка с места обрыва не продолжается, надо все заново.
Именно по причине этого идиотизма (скорее всего и впрямь коммерческой природы) и приходится до сих пор жить на FR 10 CE.
Хвала Аллаху, у нас им успели обзавестись еще до появления 11-й версии, так что поточное распознавание пока что, тьфу-тьфу, не проблема. А с учетом того, что с сайта ABBYY можно скачать относительно свежий релиз 10-й версии, в которой вычищено немало ошибок, так и совсем приличная жизнь.
Кстати, этот релиз помечен 2013-м годом (даты файлов - конец сентября). Похоже не у нас одних он такой вот долгожитель, все еще присылают баг-репорты и все еще чистят от багов.
Что же до 12-й версии, то есть интересная идея по приведению ее в нормально дееспособный вид. Покупаем FR 12 CE, ставим, регистрируем, активируем и т.д. Затем применяем лекарство от жадности.
Результаты:
- за программу честно уплачено, значит у производителя претензий быть не должно;
- при любой проверке она будет выглядеть, как нормальная лицензионная программа;
- работать можно совершенно нормально, безо всяких надуманных ограничений.
Цитата:
ЗАЧЕМ??? Единственная гипотеза -- чтобы вынудить предприятия переходить на Recognition Server
Это было вполне очевидно с самого начала. Видимо у двух отделов ABBYY - который занимается Recognition Server и который занимается обычным FR - в какой-то момент произошла нестыковка планов. И вторые не сообразили, что их новая выдумка, HotFolder - потенциальный конкурент первых.
Основное здесь недоумение - а зачем тогда вообще оставили HotFolder?
Убрали бы вообще к чертям собачьим и закрыли бы тем самым проблему. Но нет, оставили, однако всего лишь на уровне демонстрации возможностей пакетной обработки и не более того.
Цитата:
Вот только странно -- в 11-12-й все же должно было бы быть побыстрее: 1 файл в 10 минут -- это как-то совсем жестко.
Ну так сами же сказали - ограничитель по процессорному ресурсу. Убрать его - и пакетная обработка начинает работать заметно быстрее, чем в "десятке".
Правда может появиться другая проблема.
В 10-й версии HotFolder обрабатывал PDF поштучно - открыл, распознал, закрыл, открыл следующий и т.д. В 11-й и 12-й сделано по другому - сначала открывает в свой пакет _все_ PDF, лежащие в папке для обработки и только потом начинает их обрабатывать.
С этого обычно возникают две головных боли. Во-первых, место под TMP-файлы - его нужно иметь в размере всей кучки исходных PDF (причем не в объеме самих PDF, а в объеме их содержимого, пересчитанного в TIFF - открываются сканы в несжатом растре). Во-вторых, если по ходу работы HotFolder программа вдруг отрубилась (или Windows на перезагрузку вылетело), то после запуска FR обработка с места обрыва не продолжается, надо все заново.
Цитата:
Что же до 12-й версии, то есть интересная идея по приведению ее в нормально дееспособный вид. Покупаем FR 12 CE, ставим, регистрируем, активируем и т.д. Затем применяем лекарство от жадности.
Результаты:
- за программу честно уплачено, значит у производителя претензий быть не должно;
- при любой проверке она будет выглядеть, как нормальная лицензионная программа;
- работать можно совершенно нормально, безо всяких надуманных ограничений.
Т.е. Вы хотите сказать, что 12-ю можно избавить от ограничения по числу страниц и ядер процессора? Даже если бы это было возможно, ее в принципе нельзя избавить от этого нового изуверского способа работы с дисковым кэшем -- я уже через это прошел все -- сутки убил на это.
Цитата:
если по ходу работы HotFolder программа вдруг отрубилась (или Windows на перезагрузку вылетело), то после запуска FR обработка с места обрыва не продолжается, надо все заново.
Теоретически можно заставить ее складывать обработанные файлы в отельную папку. Тогда при новой "итерации" она уже не будет их обрабатывать вновь. Но вот в 10-ке почему-то эта функция просто не работает
Цитата:
Основное здесь недоумение - а зачем тогда вообще оставили HotFolder?
Убрали бы вообще к чертям собачьим и закрыли бы тем самым проблему. Но нет, оставили, однако всего лишь на уровне демонстрации возможностей пакетной обработки и не более того.
Если б Вы знали, какой там феерический бардак творится! У меня опыт и общения с ними, и инсайдерская инфа. Недавно, в качестве представителя немаленькой такой корпорации, заинтересовался их супер-новым продуктом -- искусственным их интеллектом, так сказать. Казалось бы, новый продукт, перспективный покупатель -- можно уделить ему хоть чуточку внимания. Неа, промежуток между моими вопросами и их ответами исчислялся неделями. При этом ответы были настолько мало вразумительными, что я вообще усомнился, что они знают о своем продукте хоть что-то. Что у них вообще хоть кто-то хоть что-то об этом знает. Продуктом занималась команда физтеховцев, но она, похоже, решала какие-то свои проблемы. И они, уходя, не оставили никаких инструкций

Цитата:
Ну так сами же сказали - ограничитель по процессорному ресурсу. Убрать его - и пакетная обработка начинает работать заметно быстрее, чем в "десятке".
Я имею в виду, что это ненормально даже для одного ядра -- кстати разницы в быстродействии 11-й и 12-й не увидел, несмотря на то, что в последней, вроде как, должны были два ядра разлочить. С таким быстродействием Hot Folder в принципе бесполезен.
ghosty
Цитата:
CE-вариант 12-й версии я еще не смотрел, но ее же Prof-вариант работал в полную силу, Диспетчер задач показывал полную загрузку процессора (4 ядра). В Prof правда нет HotFolder, так что приходится запускать пакетное распознавание через "Задачи". Но работает вполне толково.
Цитата:
В смысле от изряднейших размеров TMP-папки?
Здесь уже действительно ничего не сделаешь, раз заложили такую технологию обработки. Впрочем при сегодняшних объемах жестких дисков это хоть со скрипом, но решаемо. Я у себя на распознавательной машине сделал под TMP-папки отдельный раздел в пол-терабайта - пока что вполне хватает.
Цитата:
Так "обработанные файлы", в смысле отдельные PDF у 11-й и 12-й HotFolder похоже появляются только в самый последний момент. Когда распознаны все страницы всех файлов и начинается их поштучное сохранение.
А до этого просто огромная куча страниц в виде FR-пакета. Он конечно при рестарте FR подхватывается, но где в этой куче границы между отдельными файлами - после перезагрузки похоже и сам FR уже не знает.
По крайней мере в "Задачах" Prof-версии выглядит именно так. Как это же организовано в 12-м HotFolder я еще не смотрел.
Цитата:
Так в 10-ке она не особо-то и требуется.
Распознавание идет поштучно, если с программой и происходит облом, то в пределах одного PDF, не более. Смотрим на каком файле случился обвал, перемещаем все уже сделанное в выходную папку, продолжаем дальше.
Цитата:
Что за зверь таков?
Какие-то слухи о нем уже давно пробегали, но работающего продукта пока еще не видел.
Цитата:
Это-то как раз вполне понятная ситуация. Видимо вас в самом начале по ошибке связали не со специалистом именно по тамошнему ИИ, а с барышней уровня "ответим на все ваши вопросы". Которая к тому же и загружена была изрядно.
В таких случаях, как только понимаешь, что разговариваешь не с тем, с кем требуется, сразу же просишь переключить общение на нужного человека.
Цитата:
Для одного-то IMHO вполне нормально. Тем более, там идет не столько полная загрузка одного ядра, сколько одновременная загрузка всех ядер, но в сумме дающая ресурс одного ядра - я по Диспетчеру задач смотрел.
Цитата:
Почему и удивляет на кой леший его вообще оставили. 5 000 страниц в месяц плюс ограниченный процессорный ресурс - демонстрашка и не более.
Цитата:
Т.е. Вы хотите сказать, что 12-ю можно избавить от ограничения по числу страниц и ядер процессора?
CE-вариант 12-й версии я еще не смотрел, но ее же Prof-вариант работал в полную силу, Диспетчер задач показывал полную загрузку процессора (4 ядра). В Prof правда нет HotFolder, так что приходится запускать пакетное распознавание через "Задачи". Но работает вполне толково.
Цитата:
Даже если бы это было возможно, ее в принципе нельзя избавить от этого нового изуверского способа работы с дисковым кэшем
В смысле от изряднейших размеров TMP-папки?
Здесь уже действительно ничего не сделаешь, раз заложили такую технологию обработки. Впрочем при сегодняшних объемах жестких дисков это хоть со скрипом, но решаемо. Я у себя на распознавательной машине сделал под TMP-папки отдельный раздел в пол-терабайта - пока что вполне хватает.
Цитата:
Теоретически можно заставить ее складывать обработанные файлы в отельную папку. Тогда при новой "итерации" она уже не будет их обрабатывать вновь.
Так "обработанные файлы", в смысле отдельные PDF у 11-й и 12-й HotFolder похоже появляются только в самый последний момент. Когда распознаны все страницы всех файлов и начинается их поштучное сохранение.
А до этого просто огромная куча страниц в виде FR-пакета. Он конечно при рестарте FR подхватывается, но где в этой куче границы между отдельными файлами - после перезагрузки похоже и сам FR уже не знает.
По крайней мере в "Задачах" Prof-версии выглядит именно так. Как это же организовано в 12-м HotFolder я еще не смотрел.
Цитата:
Но вот в 10-ке почему-то эта функция просто не работает
Так в 10-ке она не особо-то и требуется.
Распознавание идет поштучно, если с программой и происходит облом, то в пределах одного PDF, не более. Смотрим на каком файле случился обвал, перемещаем все уже сделанное в выходную папку, продолжаем дальше.
Цитата:
заинтересовался их супер-новым продуктом -- искусственным их интеллектом, так сказать.
Что за зверь таков?
Какие-то слухи о нем уже давно пробегали, но работающего продукта пока еще не видел.
Цитата:
Неа, промежуток между моими вопросами и их ответами исчислялся неделями. При этом ответы были настолько мало вразумительными, что я вообще усомнился, что они знают о своем продукте хоть что-то.
Это-то как раз вполне понятная ситуация. Видимо вас в самом начале по ошибке связали не со специалистом именно по тамошнему ИИ, а с барышней уровня "ответим на все ваши вопросы". Которая к тому же и загружена была изрядно.
В таких случаях, как только понимаешь, что разговариваешь не с тем, с кем требуется, сразу же просишь переключить общение на нужного человека.
Цитата:
Я имею в виду, что это ненормально даже для одного ядра
Для одного-то IMHO вполне нормально
. Тем более, там идет не столько полная загрузка одного ядра, сколько одновременная загрузка всех ядер, но в сумме дающая ресурс одного ядра - я по Диспетчеру задач смотрел. Цитата:
С таким быстродействием Hot Folder в принципе бесполезен.
Почему и удивляет на кой леший его вообще оставили. 5 000 страниц в месяц плюс ограниченный процессорный ресурс - демонстрашка и не более.
Цитата:
CE-вариант 12-й версии я еще не смотрел, но ее же Prof-вариант работал в полную силу, Диспетчер задач показывал полную загрузку процессора (4 ядра). В Prof правда нет HotFolder, так что приходится запускать пакетное распознавание через "Задачи". Но работает вполне толково.
Речь именно о потоковой обработке. Короче, настроил я десятку на потоковую обработку -- более-менее стабильно идет. Учитывая, что качество меня не интересует (нужен именно текстовый массив), все нормально -- просто из-за идиотских ограничений долго провозился.
Цитата:
Что за зверь таков?
Какие-то слухи о нем уже давно пробегали, но работающего продукта пока еще не видел.
То, что у них разрабатывалось в течение лет 10 под кодовым названием Compreno. Они умудрились засунуть туда целую языковую онтологию... А зачем? А они сами не знают. Ищут (довольно лениво), вот, богатых покупателей, которым ЭТО можно было впарить, чтобы получить возможность доработать продукт, используя идиота-покупателя в качестве бета-тестера. И чтобы понять, кому и зачем ОНО может понадобиться.
Пришлось плюнуть на этого сферического коня и уйти к австрийцам -- у этих все конкретно, умно и по полочкам разложено. Приятно работать. Пусть глобальных онтологий они не создают, но у них все работает, как нужно.
В общем, как у Гераклита: многознание уму не научает. Огромные онтологии могут лишь внести кучу ненужного шума.
А вот чтобы понять, что же в ABBYY действительно происходит, мне пришлось обращаться к инсайду -- к тем, кто непосредственно принимал участие в разработке этого монстра. По-другому у нас никак.
Извините за оффтоп, но может, кому-нибудь пригодится эта информация

ghosty
Цитата:
В смысле о пакетной?
В 10-ке это заложено изначально - запускаешь HotFolder, ставишь настройки, получаешь требуемое. Основной ее минус - хронически виснет по непонятно какой причине с окошком "Распознавание выполнено на 99%". Может в таком виде хоть сутки провисеть, пока не прибьешь и не запустишь заново.
Но это вполне лечится, если поставить самый последний дистрибутив 10-ки (тот, который датирован осенью прошлого года). С ним обрабатывает практически без проблем.
Если не считать дурных объемов под TMP, то в 12-й пакетную обработку все-таки лучше делать - интерфейс более удобно организован, чем в 10-ке. Мы сейчас как раз закупаемся 12-й, если все пойдет без проблем, то можно будет на нее переехать.
Цитата:
Вполне полезная зверюшка для того, что сейчас обозначается как "Big Data". Сколько я представляю, основные интересанты здесь большие и очень большие компании с грудами плохо упорядоченных документов.
Но этим же сейчас занимаются все крупные поисковики. Уже далеко не первый год и с вполне приличными результатами на выходе. Что к уже у них сделанному может добавить Compreno - что-то не очень понятно.
Цитата:
Скорее всего именно так и есть. Приходилось слышать, что началось все с идеи отца-основателя ABBYY "а почему бы не попробовать заняться вот таким перспективным направлением - благо средства имеются".
Цитата:
Речь именно о потоковой обработке.
В смысле о пакетной?
В 10-ке это заложено изначально - запускаешь HotFolder, ставишь настройки, получаешь требуемое. Основной ее минус - хронически виснет по непонятно какой причине с окошком "Распознавание выполнено на 99%". Может в таком виде хоть сутки провисеть, пока не прибьешь и не запустишь заново.
Но это вполне лечится, если поставить самый последний дистрибутив 10-ки (тот, который датирован осенью прошлого года). С ним обрабатывает практически без проблем.
Если не считать дурных объемов под TMP, то в 12-й пакетную обработку все-таки лучше делать - интерфейс более удобно организован, чем в 10-ке. Мы сейчас как раз закупаемся 12-й, если все пойдет без проблем, то можно будет на нее переехать.
Цитата:
То, что у них разрабатывалось в течение лет 10 под кодовым названием Compreno.
Вполне полезная зверюшка для того, что сейчас обозначается как "Big Data". Сколько я представляю, основные интересанты здесь большие и очень большие компании с грудами плохо упорядоченных документов.
Но этим же сейчас занимаются все крупные поисковики. Уже далеко не первый год и с вполне приличными результатами на выходе. Что к уже у них сделанному может добавить Compreno - что-то не очень понятно.
Цитата:
А зачем? А они сами не знают.
Скорее всего именно так и есть. Приходилось слышать, что началось все с идеи отца-основателя ABBYY "а почему бы не попробовать заняться вот таким перспективным направлением - благо средства имеются".
Цитата:
В смысле о пакетной?
Да, да.
Цитата:
В 10-ке это заложено изначально - запускаешь HotFolder, ставишь настройки, получаешь требуемое. Основной ее минус - хронически виснет по непонятно какой причине с окошком "Распознавание выполнено на 99%". Может в таком виде хоть сутки провисеть, пока не прибьешь и не запустишь заново.
Да, у меня это один раз произошло, я убил ту пдфку, и теперь уже... третий день работает без остановок
Цитата:
Если не считать дурных объемов под TMP, то в 12-й пакетную обработку все-таки лучше делать - интерфейс более удобно организован, чем в 10-ке.
Ну да, просто ограничение по ядрам там убрать все же нельзя, или я не прав?
Цитата:
Вполне полезная зверюшка для того, что сейчас обозначается как "Big Data". Сколько я представляю, основные интересанты здесь большие и очень большие компании с грудами плохо упорядоченных документов.
Но этим же сейчас занимаются все крупные поисковики. Уже далеко не первый год и с вполне приличными результатами на выходе. Что к уже у них сделанному может добавить Compreno - что-то не очень понятно.
Там не все так однозначно. Поисковики -- это по-прежнему именно универсальные индексаторы. Compreno -- это система "извлечения сущностей". Для того, чтобы сущности извлекались правильно, должны быть определенные правила, семантика. В Compreno я могу лишь с очень большим трудом -- по большей части через их инженеров -- править эти самые правила (они видимо, считают, что так им будет выгоднее -- клиент всегда зависим и привязан к ним). А по-хорошему, я должен быть полностью независим в построении онтологий. Вот к такой системе я и дрейфую сейчас. Кстати, в Австрии со мной изначально общаются исключительно менеджеры высшего звена, а не "деффачки", которых посадили на телефон. Это при том, что компания -- один из лидеров в области. Вот такое разительное отличие в подходах
ghosty
Цитата:
Можно конечно, я же об этом и говорил. Применяете лекарство и оба ограничителя (на процессорный ресурс и на количество страниц) исчезают.
Пока проверял в этом смысле только Prof-версию, надо будет и Corp тоже посмотреть.
А если программа при этом еще и честно куплена, так вообще никаких проблем.
Цитата:
Которые, как правило, надо долго и нудно настраивать и подстраивать под именно свою конкретику, доводить до нормальной работоспособности и т.д.
От производителя в этом смысле обычно приходит только движок с умолчательным набором настроек, а всю рабочую доводку делает пользователь. И именно поэтому гибкость и удобство управления настройками здесь можно считать одним из ключевых требований к программе.
Цитата:
Подозреваю, что это не столько чей-то умысел, сколько нормальное состояние только что слепленной программы.
Большая часть управления - чуть ли не через правку кода, более или менее нормальный интерфейс только планируется, удобное управление и хорошая настраиваемость - что-то вроде светлого коммунистического будущего.
В общем версия 1.0, альфа-релиз.
Цитата:
Ну да, просто ограничение по ядрам там убрать все же нельзя, или я не прав?
Можно конечно, я же об этом и говорил. Применяете лекарство и оба ограничителя (на процессорный ресурс и на количество страниц) исчезают.
Пока проверял в этом смысле только Prof-версию, надо будет и Corp тоже посмотреть.
А если программа при этом еще и честно куплена, так вообще никаких проблем.
Цитата:
Compreno -- это система "извлечения сущностей". Для того, чтобы сущности извлекались правильно, должны быть определенные правила, семантика.
Которые, как правило, надо долго и нудно настраивать и подстраивать под именно свою конкретику, доводить до нормальной работоспособности и т.д.
От производителя в этом смысле обычно приходит только движок с умолчательным набором настроек, а всю рабочую доводку делает пользователь. И именно поэтому гибкость и удобство управления настройками здесь можно считать одним из ключевых требований к программе.
Цитата:
В Compreno я могу лишь с очень большим трудом -- по большей части через их инженеров -- править эти самые правила (они видимо, считают, что так им будет выгоднее -- клиент всегда зависим и привязан к ним).
Подозреваю, что это не столько чей-то умысел, сколько нормальное состояние только что слепленной программы.
Большая часть управления - чуть ли не через правку кода
, более или менее нормальный интерфейс только планируется, удобное управление и хорошая настраиваемость - что-то вроде светлого коммунистического будущего. В общем версия 1.0, альфа-релиз.

Обучаю эталон, а некоторые символы полностью помещаются в рамку только вместе с частью соседнего символа. Сейчас, такие символы добавляю в эталон целыми кластерами, создавая новые лигатуры. Есть ли лучший вариант? Ведь, сочетаний букв гораздо больше чем самих букв.
При просмотре эталона, некоторые символы (фонетические) не отображаются. Однако, многие из них отображаются при просмотре алфавита языка. Можно ли настроить отображение этих символов и в эталоне?


Ves
Цитата:
Когда перекрытие не очень большое, то FineReader иногда подправляет сам себя - прилегающий кусочек соседнего символа в текущий символ не включает.
Но если перекрывается так основательно, как у вас на примере, то боюсь, что здесь ничего не сделаешь, кроме как лигатуру сооружать.
Цитата:
Есть ли лучший вариант?
Когда перекрытие не очень большое, то FineReader иногда подправляет сам себя - прилегающий кусочек соседнего символа в текущий символ не включает.
Но если перекрывается так основательно, как у вас на примере, то боюсь, что здесь ничего не сделаешь, кроме как лигатуру сооружать.
Страницы: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104
Предыдущая тема: filesCatalog
Форум Ru-Board.club — поднят 15-09-2016 числа. Цель - сохранить наследие старого Ru-Board, истории становления российского интернета. Сделано для людей.