SFC
Спасибо за колоду! Очень круто, что сделана на основе CLDER и с отдельными карточками для отдельных значений. Пытаясь проходить колоду на основе частотного списка пришел к таким же выводам. В итоге, на разделение значений ума и мотивации не хватило, а вместо обратной стороны использовал словарную оболочку с CLDER и OBAD.
Но, это был этап в эволюции моих представлений о правильном решении. Теперь идеальным вариантом кажется, такой при котором примеры будут вынесены со стороны ответа на сторону вопроса, а нужное слово чем-то выделено. Преимуществ несколько. Четче определенный контекст не позволяет перепутать значение. Используемые в вашей колоде уточнения значений, по сути, являются пометками для быстрой навигации в словарных статьях и играют роль подсказок. Т.е страдает важный компонент spaced repetition - припоминание. Также эти уточнения сложно воспринимать, если они грамматические. Получается в одном случае слишком легко, в другом - сложно. Правда, если применить примеры в качестве вопросов, их придётся "резать" до одного, так как ситуация, в которой, статистика одного значения распределена между разными карточками - неправильна. Если отбросить технические препятствия(не уверен есть ли такие в anki), то отличным вариантом был бы рандом всех примеров(имеющихся у данного значения) внутри лицевой стороны одной карточки относящейся к одному значению.
Спасибо за колоду! Очень круто, что сделана на основе CLDER и с отдельными карточками для отдельных значений. Пытаясь проходить колоду на основе частотного списка пришел к таким же выводам. В итоге, на разделение значений ума и мотивации не хватило, а вместо обратной стороны использовал словарную оболочку с CLDER и OBAD.
Но, это был этап в эволюции моих представлений о правильном решении. Теперь идеальным вариантом кажется, такой при котором примеры будут вынесены со стороны ответа на сторону вопроса, а нужное слово чем-то выделено. Преимуществ несколько. Четче определенный контекст не позволяет перепутать значение. Используемые в вашей колоде уточнения значений, по сути, являются пометками для быстрой навигации в словарных статьях и играют роль подсказок. Т.е страдает важный компонент spaced repetition - припоминание. Также эти уточнения сложно воспринимать, если они грамматические. Получается в одном случае слишком легко, в другом - сложно. Правда, если применить примеры в качестве вопросов, их придётся "резать" до одного, так как ситуация, в которой, статистика одного значения распределена между разными карточками - неправильна. Если отбросить технические препятствия(не уверен есть ли такие в anki), то отличным вариантом был бы рандом всех примеров(имеющихся у данного значения) внутри лицевой стороны одной карточки относящейся к одному значению.
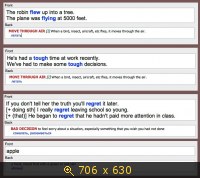

 Про него раньше не слышал и в свое время решил не устанавливать.
Про него раньше не слышал и в свое время решил не устанавливать.