Отдельной темы в Программах для ABBYY Screenshot Reader нет, может кто подскажет, из-за чего может не работать Screenshot Reader начиная с 11-той версии при захвате Области (Win 7 x86) ? Причём, не важно что сохранять: текст, изображение, таблицу в буфер обмена или в файл. При выделении области сохранение не происходит, сразу появляется окошко программы. В режиме сохранения Окна, Экрана всё работает как надо. В версиях от 10-й и ниже проблем нет.
» ABBYY FineReader
В FR12 та же фигня что и в 11-ой. При сохранении в DjVu надо использовать FR11 DjVu Text Layer Crutch → http://forum.ru-board.com/topic.cgi?forum=5&topic=38467
В ФР12 не нахожу горячего переключения вида распознанного: "Точная копия - Форматированный текст - ...". В версиях до 12-й была. А сейчас не вижу. Или не там смотрю?
Днём позже: нашёл.
Днём позже: нашёл.
А как ABBYY FineReader 12.0.101.264 Professional Edition корректно удалить? Что-то я не нашел uninstall ни в Программах, ни в директории Finereader. При повторном запуске установки предлагает или изменить, или исправить, а вот про удаление молчит.
timhome
Пардон. Действительно, повторный запуск установщика не поможет.
Поможет запуск setup.exe /x из каталога установки.
Либо Пуск-Настройка-Панель управления-Установка и удаление программ.
(Пуск-Выполнить- вставить строку: rundll32 shell32,Control_RunDLL appwiz.cpl и нажать [ENTER].
Там на FineReader 12 будет доступно две опции: [Изменить] | [Удалить].
Пардон. Действительно, повторный запуск установщика не поможет.
Поможет запуск setup.exe /x из каталога установки.
Либо Пуск-Настройка-Панель управления-Установка и удаление программ.
(Пуск-Выполнить- вставить строку: rundll32 shell32,Control_RunDLL appwiz.cpl и нажать [ENTER].
Там на FineReader 12 будет доступно две опции: [Изменить] | [Удалить].
ALEX666999
Спасибо.
Спасибо.
Установил на планшет ElitePad p900, но finereader 12 не видит камеру планшета. На планшете Windows 8.1 x86. Можно ли сделать так чтобы finereader Увидел камеру планшета?
Как то можно конвертировать в нормальный текстовый формат слова из файла C:\Users\...\AppData\Roaming\ABBYY\FineReader\12.00\UserDictionaries\*.ame ?
Т.е. из персонального словаря.
Т.е. из персонального словаря.
в 12ой версии есть возможность автообрезки по краям страницы?
нашел только в настройках предварительной обработки "определить края страниц".
Хотя тут написано
http://www.abbyy.ru/finereader-professional/new/
что есть "Автоматическое обрезание лишних частей изображения для всех страниц"
нашел только в настройках предварительной обработки "определить края страниц".
Хотя тут написано
http://www.abbyy.ru/finereader-professional/new/
что есть "Автоматическое обрезание лишних частей изображения для всех страниц"
Lexan5
Вы об этом?
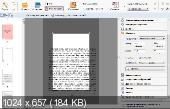
Вы об этом?

hogu77
нет, это ручное обрезание. Мне нужно автоматически обрезать изображения по краям страниц
нет, это ручное обрезание. Мне нужно автоматически обрезать изображения по краям страниц
ABBYY FineReader научился распознавать почерк врачей http://www.abbyy.ru/Default.aspx?DN=2b5288d9-9eb1-4334-b770-04193a5c02ba
Они это серьезно? Почему подпись на скриншоте вообще никак не распознана? Насколько я понимаю , "почерк врачей" - не стенография, а свои собственные, личные каракули
Они это серьезно? Почему подпись на скриншоте вообще никак не распознана? Насколько я понимаю , "почерк врачей" - не стенография, а свои собственные, личные каракули
laprad
Написано же в новости: "С 1 апреля!"
Написано же в новости: "С 1 апреля!"
Antonij72
Цитата:
Да, не углядел. Удачная шутка, правдоподобная. Наверное, на самом деле все-таки пытались, но приемлемого результата пока не получили.
Цитата:
Написано же в новости: "С 1 апреля!"
Да, не углядел. Удачная шутка, правдоподобная. Наверное, на самом деле все-таки пытались, но приемлемого результата пока не получили.
Лично я всё жду корректного распознавания таблиц (которые без границ), а также вытаскивание (а не распознавание!!!) текста из "правильных" (которые не из картинок, а как положено: из нормального текста, который "видят" все конвертеры) pdf-ок...
Здравствуйте! Скачал вчера ABBYY FineReader 12 Professional.
При сканировании окошко выходит же, где можно выбрать 300 dpi Серый, цветной или чёрно-белый, настройки и т.д.
Раньше это окошко не закрывалось и если нет цветных фото, то можно было нажимать просто на кнопку "Сканировать" или просто жать кнопку "Enter" что было легко.
Сейчас это окошко закрывается постоянно. Приходится наверху жать на кнопку "Сканировать" и затем в открывшемся окошке снова жать на "Сканировать", что страшно раздражает и неудобно и долго.
Как сделать, чтобы это окошко не исчезало. Все настройки облазил - не нашёл. Спасибо.
Добавлено:
Стоит Windows 7 Ultimate x64 SP1.
При сканировании окошко выходит же, где можно выбрать 300 dpi Серый, цветной или чёрно-белый, настройки и т.д.
Раньше это окошко не закрывалось и если нет цветных фото, то можно было нажимать просто на кнопку "Сканировать" или просто жать кнопку "Enter" что было легко.
Сейчас это окошко закрывается постоянно. Приходится наверху жать на кнопку "Сканировать" и затем в открывшемся окошке снова жать на "Сканировать", что страшно раздражает и неудобно и долго.
Как сделать, чтобы это окошко не исчезало. Все настройки облазил - не нашёл. Спасибо.
Добавлено:
Стоит Windows 7 Ultimate x64 SP1.
И ещё - сейчас можно в последней 12 версии сканировать с отключёнными настройками всеми предобработки (кроме автоматического поворота двойной страницы)? А то у меня IrfanView не работает как надо (закрывается окно сканирования после одного прохода).
Чтобы потом загрузить в SkanKromsator и спокойно обработать дабы потом перевести в DjVu. В 6-7-8 версиях говорят FineReader портил сканы (т.е. они отличались от тех, что отсканированы с помощью IrfanView и иже с ними прогами). Сейчас в 12 версии может можно уже сканировать, сканы не будут уже "портиться"?
Чтобы потом загрузить в SkanKromsator и спокойно обработать дабы потом перевести в DjVu. В 6-7-8 версиях говорят FineReader портил сканы (т.е. они отличались от тех, что отсканированы с помощью IrfanView и иже с ними прогами). Сейчас в 12 версии может можно уже сканировать, сканы не будут уже "портиться"?
Подскажите, пожалуйста, есть ли какие-то тонкости при массовой обработке в ABBYY FineReader или же это глюк, которым разрабы гордятся?
Создаю и запускаю задачу - распознание нескольких pdf-файлов. Перед непосредственно распознанием идёт стадия анализа. На этой стадии через некоторое время (примерно, после 1000 страниц) - FineReader радостно заявляет, что "Не хватает памяти", потом - "Отсутствуют страницы для анализа", процесс останавливается, программа подвисает. Памяти, разумеется, - выше крыши - RAM 32 Гб (из них FR где-то 3 Гб съедает), места на диске с Temp каталогом - более 100 Гб. Windows 8.1 x64 SL, FR 12.0.101.264
Так было и в 11 версии, сейчас установил 12 - те же пироги.
Это решаемый вопрос? Может, в настройках что-то где-то выставить, чтобы FR не плющило?
Создаю и запускаю задачу - распознание нескольких pdf-файлов. Перед непосредственно распознанием идёт стадия анализа. На этой стадии через некоторое время (примерно, после 1000 страниц) - FineReader радостно заявляет, что "Не хватает памяти", потом - "Отсутствуют страницы для анализа", процесс останавливается, программа подвисает. Памяти, разумеется, - выше крыши - RAM 32 Гб (из них FR где-то 3 Гб съедает), места на диске с Temp каталогом - более 100 Гб. Windows 8.1 x64 SL, FR 12.0.101.264
Так было и в 11 версии, сейчас установил 12 - те же пироги.
Это решаемый вопрос? Может, в настройках что-то где-то выставить, чтобы FR не плющило?
LonerDergunov
Очень смахивает на ограничения 32-разрядного приложения.
Очень смахивает на ограничения 32-разрядного приложения.
Цитата:
Очень смахивает на ограничения 32-разрядного приложения.
Насколько я понимаю - тогда было бы ограничение на 2 гига оперативки.
Теоретически авторы такой сурьёзной программы должны были как минимум недопустить краха работы из-за банального переполнения памяти. Не обязательно ведь обрабатывать ВСЕ поставленные в очередь файлы одновременно. Обработали порцию - сохранили - освободили память - обработали следующую порцию.
Добавлено:
Вопрос попроще.
FineReader может распознать буквы/цифры, размер которых отличается от остального текста (буквицы, например)? Если может - то каким образом его настроить для этого?
Пробую в версии FR 12.0.101.264 простенький, чёткий и недвузначный текст:
http://rghost.ru/55641212.view
Акробат его - ноу проблем - распознаёт прекрасно.
Файнридер с языками русский+английский+цифры - разрыв шаблона:
http://rghost.ru/55641415.view
Пробую выбирать другие языки - лучше не становится ((
PS. Очень странно. Нашёл 8, 9 версии - там получше дела обстоят, правда все цифры при выделении распознанного текста идут подряд, но они распознаются хотя бы, а не слипаются со строками...
PPS. В 12 версии выбрал чёрно-белое отображение чёрно-белых страниц. Стало немного лучше. Кое-где почему-то стали распознаваться такие вот буквицы..
LonerDergunov А распознать указанный вами текст как табличный блок не пробовали? Ведь фактически это таблица без границ ячеек.
Цитата:
Пробую в версии FR 12.0.101.264 простенький, чёткий и недвузначный текст:
http://rghost.ru/55641212.view
Screenshot Reader той же версии распознает на этой картинке нормально, только если цифры отдельно выделить.
Может будет лучше если изменить в редакторе FR разрешение, раз в десять больше или меньше.
Maikl65
Я ведь потому и спрашиваю, что не нашёл такой настройки в программе. Как выставить автоматическое определение таких текстов как таблиц? Если выделить вручную и отметить таблицу - то распознаёт. Но не вручную ведь каждую зону обводить (обрабатывать много надо). Тем более, что в старых версиях FR эти же страницы распознавались нормально.
inapht
При увеличении разрешения в некоторых случаях становится немного лучше. Но в целом - ситуация та же самая.
Я ведь потому и спрашиваю, что не нашёл такой настройки в программе. Как выставить автоматическое определение таких текстов как таблиц? Если выделить вручную и отметить таблицу - то распознаёт. Но не вручную ведь каждую зону обводить (обрабатывать много надо). Тем более, что в старых версиях FR эти же страницы распознавались нормально.
inapht
При увеличении разрешения в некоторых случаях становится немного лучше. Но в целом - ситуация та же самая.
Мда... Почитал про разные версии...
Оказывается, разработчики - алхимики. "Чтобы получить что-то - нужно отдать что-то равноценное в обмен". Или если перефразировать "Чтобы ввести в программу полезную возможность - нужно выкорчевать другую полезную возможность".
"Чтобы получить что-то - нужно отдать что-то равноценное в обмен". Или если перефразировать "Чтобы ввести в программу полезную возможность - нужно выкорчевать другую полезную возможность".
В последних версиях взяли и выкорчевали автоматическое распознание зон текста и картинок, табличного представления текста...
Вот ещё примерчик:
http://rghost.ru/55703230
FR9 находит на странице и распознаёт немало текста (в чёрно-белом режиме). FR12 уже на такое оказался неспособен ((
Оказывается, разработчики - алхимики.
"Чтобы получить что-то - нужно отдать что-то равноценное в обмен". Или если перефразировать "Чтобы ввести в программу полезную возможность - нужно выкорчевать другую полезную возможность". В последних версиях взяли и выкорчевали автоматическое распознание зон текста и картинок, табличного представления текста...
Вот ещё примерчик:
http://rghost.ru/55703230
FR9 находит на странице и распознаёт немало текста (в чёрно-белом режиме). FR12 уже на такое оказался неспособен ((
Цитата:
Очень смахивает на ограничения 32-разрядного приложения.
Очень смахивает на абсолютную неоптимальность инструмента групповой обработки.
Насколько я понял, чёрно-белые страницы распознаются чуть более уверенно. И на обработку требуется меньше ресурсов (как оперативки, так и места во временном каталоге). Выбрал шесть файлов - обработка заняла порядка 15 минут, памяти потребляется мало - ОК, значит можно и больше "нагрузить". Выбираю порцию восемь файлов - але-оп - обработка длится около часа, FR регулярно надолго задумывается и подвисает.
LonerDergunov 02:30 23-05-2014
Цитата:
Цитата:
Насколько я понимаю - тогда было бы ограничение на 2 гига оперативки.Operу 32-разрядную начинает колбасить при достижении 3.5Гб.
Здравствуйте как распознать транскрипцию в ABBY FineReader
Littlefox97
Обучать.
По теме - http://forum.ykt.ru/mviewtopic.jsp?id=1839889&f=44
Киньте пожалуйста страничку с транскрипцией на rghost или куда там вам удобнее.
Обучать.
По теме - http://forum.ykt.ru/mviewtopic.jsp?id=1839889&f=44
Киньте пожалуйста страничку с транскрипцией на rghost или куда там вам удобнее.
LonerDergunov
Цитата:
Такой вопрос. Может ли кто-нибудь отдельно выложить старорусский язык для 12-го файнридера? А то я репак скачал, а там нету. Должно быть три файла с расширениями *.amd, *.amm, *.amt. Буду очень признателен!
Цитата:
Вопрос попроще.Уважаемый, картинка, которую ты выложил, это НЕ текст, это ТАБЛИЦА. Только что выделил область как таблицу и всё распозналось на ура - "ни единого разрыва" (с)
FineReader может распознать буквы/цифры, размер которых отличается от остального текста (буквицы, например)? Если может - то каким образом его настроить для этого?
Пробую в версии FR 12.0.101.264 простенький, чёткий и недвузначный текст:
http://rghost.ru/55641212.view
Акробат его - ноу проблем - распознаёт прекрасно.
Файнридер с языками русский+английский+цифры - разрыв шаблона:
http://rghost.ru/55641415.view
Пробую выбирать другие языки - лучше не становится ((
Такой вопрос. Может ли кто-нибудь отдельно выложить старорусский язык для 12-го файнридера? А то я репак скачал, а там нету. Должно быть три файла с расширениями *.amd, *.amm, *.amt. Буду очень признателен!
warezo
Они? - http://rghost.ru/56021699
Они? - http://rghost.ru/56021699
Страницы: 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104
Предыдущая тема: filesCatalog
Форум Ru-Board.club — поднят 15-09-2016 числа. Цель - сохранить наследие старого Ru-Board, истории становления российского интернета. Сделано для людей.